The Privacy Architecture Behind Data Mining: Why Your Raw Data Never Leaves Your Device

If someone told you there's a browser extension that earns you passive income just by being installed — no setup, no extra steps — your first reaction probably wouldn't be excitement. It would be suspicion.
That's a reasonable response.
Over the past decade, the "free service + data collection" business model has trained users to be reflexively wary. Every internet product you use is collecting your data in ways you can't see, then monetizing it in places you'll never know about. You're not the user — you're the product. That line has been repeated for years, but it's never been more true than it is today.
So when we announced that DataDID was launching its Data Mining module — a feature that lets users convert their browsing behavior into point-based rewards — the first question we had to answer wasn't "how are points calculated" or "how much can I earn." It was: "Is my data safe?"
This post answers that question from the ground up.
What We Collect — and What We Don't
Bottom line first: the Data Mining module collects signals from the public behavioral layer of your browser. It does not touch account credentials, personal identity information, the content of what you browse, or any private data.
Specifically, the system identifies and records locally: the domain of each website you visit, how long you stay on that page, and which content category that domain belongs to. All of these signals come from a layer of the browser that is publicly observable by any extension running in it — what types of sites you visit, which pages hold your attention longer, how your interests shift across different content categories. The difference between us and other actors is this: others take that data and build advertising profiles. We run the entire processing pipeline locally, and only send out a mathematical proof.
Two details are worth calling out explicitly.
First, we cannot see what you're actually reading. The specific articles you read, the videos you watch — none of that is within the scope of collection by design. We don't need to know what you're looking at. We only need to know what type of site you're visiting and whether your browsing pattern is diverse.
Second, the system has strict anti-gaming mechanisms built in: pages you spend fewer than 5 seconds on don't count as valid visits, and sub-pages under the same second-level domain are consolidated into a single entry. The underlying logic is that high-quality behavioral data comes from genuine, meaningful browsing — not mechanical page-hopping.
What ZK Proofs Do: Why a "Proof" Is Not the Same as "Data"
What genuinely sets Data Mining's privacy architecture apart from conventional data collection is zero-knowledge proofs (ZK Proofs).
The concept might sound abstract, but the principle is straightforward.
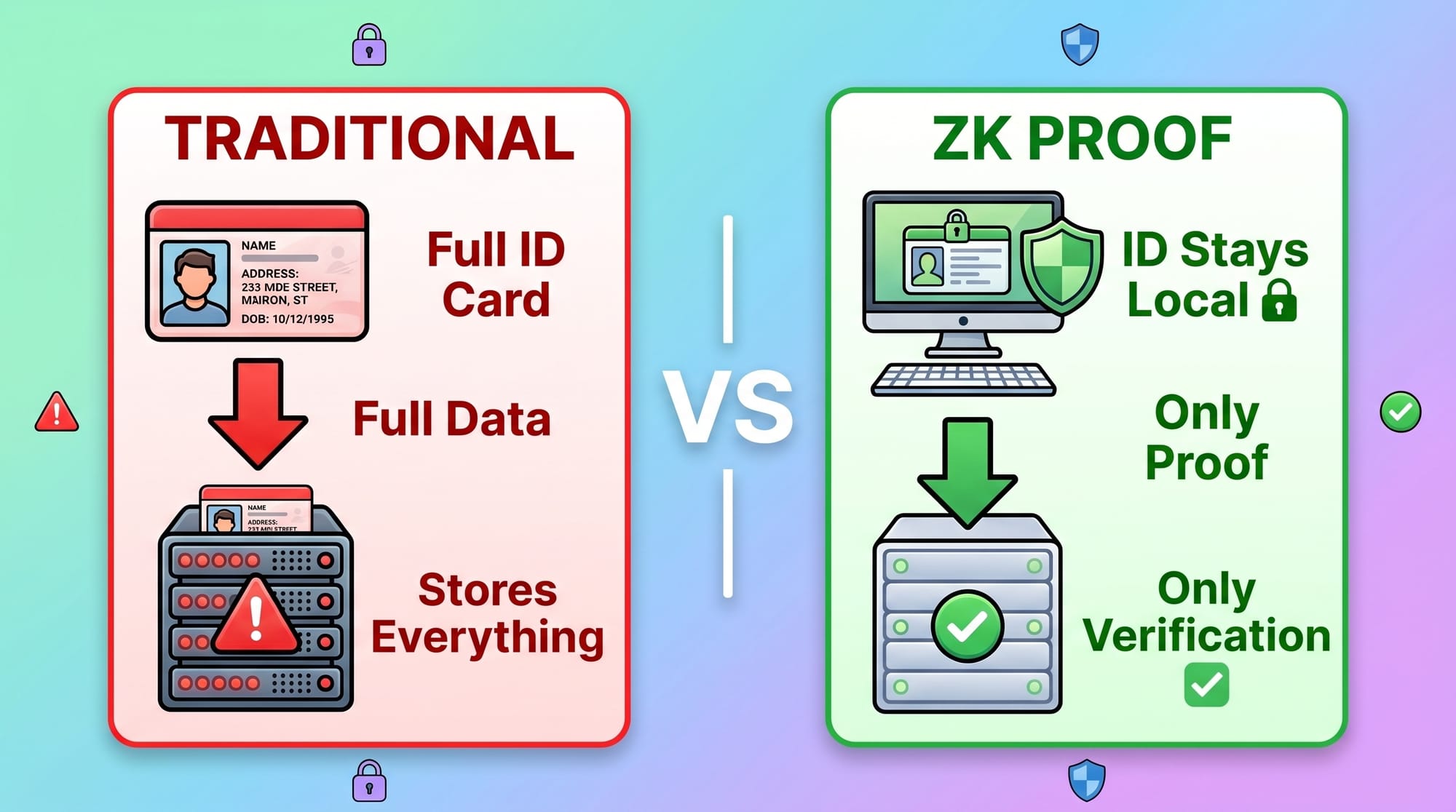
The traditional approach: the data collector takes your data, stores it on their servers, then tells buyers "this data is real." In that pipeline, your data has already been copied in full and handed off. What happens to it next — where it's stored, how it's used, when it gets deleted — depends entirely on the collector's integrity. You have no actual control.
Our approach: all raw data processing happens locally on your device. A ZK circuit then generates a mathematical proof. That proof can verify something like: "This user visited 20 distinct domains in the past 24 hours, spanning more than 5 content categories, with all visits representing genuine browsing sessions of at least 5 seconds." But it cannot be reverse-engineered to reveal which specific sites you visited, in what order, or at what time.
One sentence captures the difference: traditional systems export your data. ZK systems export a proof about your data.
A commonly used analogy: you walk into a bar and the bouncer needs to confirm you're 21 or older. The traditional approach — you hand over your ID, which has your birthdate, name, home address, and photo. The ZK approach — you present a mathematical proof that states "this person's age ≥ 21," nothing more. The bouncer gets what he needs. You keep everything you didn't need to share.
When designing Data Mining's architecture, we faced essentially the same trade-off. What does the AI training data market actually need? Not the specific articles you read — it needs the signal that "this is a real user with diverse browsing behavior." The value of that signal comes from its diversity and authenticity, not from its specificity.
So raw data never leaves your device. What goes on-chain is only the verification credential generated by the ZK Proof — a cryptographic "mathematical attestation" that records your behavioral diversity but cannot be used to reconstruct your browsing history. That was the design boundary we drew from the very beginning and never moved.
Why the Toggle Defaults to Off
One decision during Data Mining's product design generated significant internal debate: should the data incentive module default to on or off?
Default-on means zero friction for the user and much better early participation numbers. That's almost conventional wisdom in internet product design — every additional step in a flow causes meaningful drop-off.
We chose default-off anyway.
The reason is simple: data collection is in the middle of a global trust crisis. GDPR has levied over €4.5 billion in cumulative fines. Regulators across jurisdictions are tightening provenance requirements for AI training data. The "collect first, notify later" product logic is being systematically challenged. In that environment, a data-related product where users have to discover for themselves that they even have a choice — that product has already compromised its own credibility before it's shipped.
So the first time you enable the Data Mining module, the plugin surfaces a clear authorization screen that specifies exactly what signals are collected, what they're used for, and that you can turn off the toggle and revoke consent at any time. Turning it off stops collection immediately. Accumulated points are not cleared.
We believe the path forward for the data economy isn't using better technology to collect data more invisibly. It's using stronger mechanisms to genuinely return data control to users. That sounds like a platitude, but at the product level it comes down to a single concrete choice: default-off instead of default-on.
The Last Line of Defense: No Raw Data Stored Server-Side
There's one more detail that's easy to overlook but critical to the privacy architecture: DataDID's servers do not store users' raw browsing behavior data.
This means that even in the most extreme scenario — a successful attack on DataDID's backend — what an attacker could access would be only the on-chain ZK Proof verification credentials. There would be no browsing records to reconstruct, because the raw data never left users' local devices in the first place.
This is the most fundamental distinction between privacy by design and privacy by promise. A promise is a sentence in a whitepaper. A design is a physical constraint baked into the system architecture. Promises can be broken. Architectural constraints cannot be circumvented — even the system administrators themselves have no access to data that was never stored on the servers.
This is why, at the architecture design stage, we chose a fully local ZK Proof approach rather than uploading data to a server for "de-identification processing." The latter would have been more cost-efficient in operational terms — running ZK circuits on centralized server hardware is far more efficient than running them distributed across user devices. But the cost savings would have come at the price of a security gap: the moment data leaves a user's device, it no longer belongs entirely to that user.
A Final Note
As a product, the Data Mining module is a points incentive tool. But from where we started, it's closer to an experimental proof of concept. The proposition we wanted to test: can a product that helps users earn returns from their data, and a technical architecture that fully respects user privacy, coexist?
That sounds like walking a tightrope. But the maturation of ZK Proof technology has made that rope considerably thicker than it was a few years ago.
Users have never been bystanders in the data economy. They've simply never had the tools — a mechanism that lets them participate in data value distribution without surrendering their privacy. Data Mining is our first answer to that problem.
It's not perfect. But the direction is right. The rest is up to time.
DataDID is MEMO's decentralized data identity system. It enables on-chain confirmation and circulation of data assets through the ERC-7829 protocol. The Data Mining module is now live in the DataDID browser extension.