How ZK Proofs Became the Last Real Line of Defense for Data Privacy

In 2024, cumulative GDPR fines in the EU surpassed €4.5 billion.
That same year, the U.S. Copyright Office began re-examining the fair use boundaries of AI training data. The New York Times sued OpenAI, demanding the destruction of model weights trained on its content. Japan revised its Act on the Protection of Personal Information to bring browsing behavior data under regulatory scope.
If you're a product manager at any internet company, you can feel the shift. Three years ago, saying "we protect user privacy" was a PR statement. Today, saying it means you need to open up your technical architecture and show your work. Regulators, investors, and users are all applying increasingly rigorous standards to determine whether "privacy" actually means anything.
Inside the DataDID team, when we talk about ZK Proofs, we keep coming back to one analogy.
It's not a door lock. It's a load-bearing wall.
A door lock can be picked. It can be bypassed by someone with admin access. It can be accidentally disarmed during a maintenance incident. A load-bearing wall can't. Tear it down and the building collapses. That's not a permissions issue — it's a physical constraint.
This post is about how that wall gets built, and why it may be the only truly reliable line of defense we have in data privacy.
The Three Paths the Industry Has Tried — and Where Each One Breaks
The internet industry currently has roughly three approaches to protecting user data. Each has its own fatal flaw.
Path one: encryption. TLS in transit, AES at rest, clean key rotation practices. The problem is that encryption protects data while it's being transmitted or stored — but the moment the server needs to use the data, for analysis, matching, or recommendations, it has to decrypt first. The instant it decrypts, the data is vulnerable again. Encryption is the lock on the cabinet, but you always have to open the cabinet to get at what's inside.
Path two: de-identification. Strip direct identifiers — name, phone number, national ID — and retain an anonymized user profile. The problem here is subtler but more serious. De-identification is not the same as anonymization. A substantial body of academic research has shown that with enough auxiliary information, so-called anonymous data can be re-identified with considerable precision. In 2006, the "anonymous" search logs AOL released publicly were traced back to specific individuals by New York Times reporters within days. In 2007, researchers at the University of Texas cross-referenced the anonymous rating data from the Netflix Prize dataset with public IMDb ratings and reconstructed user identities. De-identification is a thin veil, not a wall.
Path three: compliance. User agreements, privacy pop-ups, a stack of documentation ready for a GDPR audit. This is the lowest-effort path and, by far, the most common. The problem is simple: compliance answers the question of who's liable when something goes wrong — not whether something can go wrong. It's a legal defense, not a technical one.
Step back from all three, and a shared blind spot emerges. Every one of them tries to protect privacy after the data has already been collected and uploaded to a server. They protect data once it reaches the server. But the moment data leaves a user's local device, its fate is in someone else's hands.
This is where ZK Proofs do something fundamentally different.
The Bar Analogy — Because It's Still the Clearest Explanation
Before getting into the technical specifics, the bar example. It gets used a lot, and for good reason — it's genuinely the most intuitive way to understand what's happening.
You walk into a bar. The bouncer needs to confirm you're 21 or older. The traditional approach: you hand over your ID, which contains your name, date of birth, photo, and home address. To prove one single thing — "I am at least 21" — you've handed over a bundle of information with zero connection to your age. That information is now in the bouncer's hands. You might trust him, but can you trust every app on his phone that might scan it? Can you trust that the bar's database won't be breached three years from now?
The ZK Proof approach flips this entirely. It gives you a mathematical tool that generates a proof: "This person's age is greater than or equal to 21." Nothing else. The bouncer verifies the proof, gets the answer he needed, and learns nothing about your actual age, your name, or your address. You exposed exactly the necessary information — not one word more.
That's the core insight. Traditional privacy protection asks: "How can we safely do things with this pile of data?" ZK Proof asks: "Can we get the job done without ever needing this pile of data in the first place?" The former is damage control after data already exists. The latter eliminates the need for the data to leave your device at all.
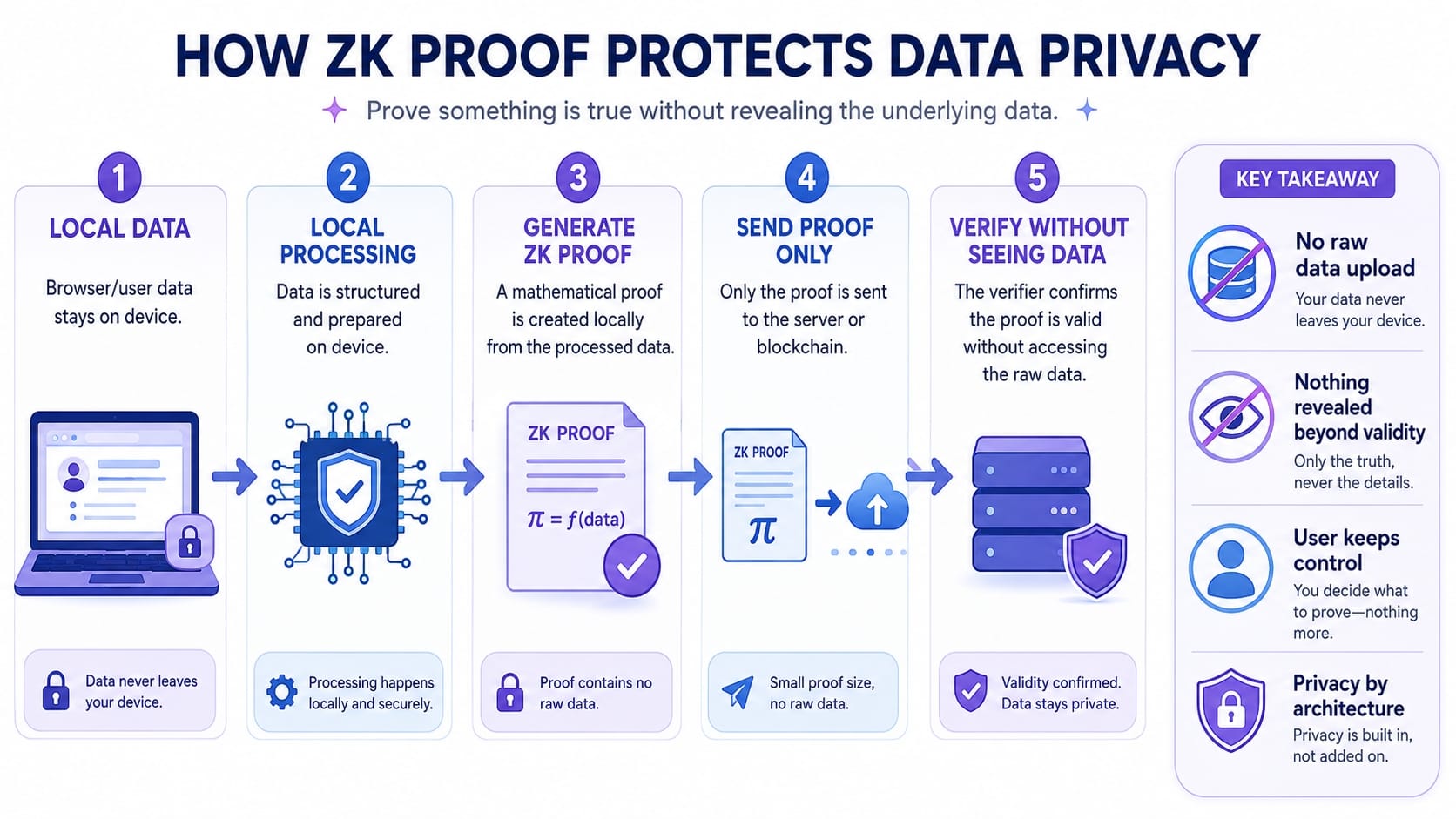
When we designed DataDID's Data Mining module, we faced the same structural question. What does the AI training data market actually need? Not "which five tech articles did this user read today" — it needs the signal that "this is a real user with diverse browsing behavior." That signal can be carried by a mathematical proof. The raw data never needs to leave your device.
How This Works in Practice Inside DataDID
When a user enables the Data Mining module, the system completes three steps entirely on the user's local device.
Step one: identify signals from the public behavioral layer of the browser — which categories of sites were visited, how long was spent on each page, which interest domains the content covered. Step two: feed those behavioral signals into a local ZK circuit and generate a mathematical proof. Step three: upload the proof to the chain; the raw behavioral data is automatically discarded locally.
Throughout the entire process, what the server receives is a single cryptographic attestation. It can verify that the attestation genuinely came from a legitimately authorized client, and that the behavioral diversity metrics it describes are statistically plausible — but it cannot reconstruct any specific browsing record from that proof. The proof is zero-knowledge: the verifier learns nothing beyond "this proof is valid."
This distinction is worth stating precisely, because it gets confused often.
Encryption and ZK Proofs both involve cryptography, but they solve opposite problems. Encryption solves "only authorized parties can see this." ZK solves "nobody needs to see this at all." Encryption protects the confidentiality of data. ZK eliminates the need for the data to be seen in the first place.
The difference between de-identification and ZK Proofs is even more fundamental. De-identification processes the original data — but the original data still traveled to the server. The ZK approach means the raw data was never transmitted. This isn't "we processed your data until no one can recognize it." This is "your data never left your device. What was sent is a mathematical summary about your data."
In DataDID's architecture, the server holds no browsing records. Not "we deleted the records" — "the records were never uploaded." Those two statements sound similar. In security engineering, they are separated by the entire history of internet privacy.
Back to the Load-Bearing Wall
Why is ZK Proof a load-bearing wall rather than a door lock?
Because a door lock is a management mechanism. An administrator can unlock it today. A database admin can bypass it. An internal bad actor can circumvent it. A court order can compel it to be opened. Any system that depends on "permissions being correctly configured" and "administrators not making mistakes" is permanently fragile. It doesn't get broken by technology — it gets broken by human nature.
A load-bearing wall is different. It's a structural constraint.
In DataDID's architecture, "raw data stays local" is not a setting that can be toggled off. It's not a policy switch that can be flipped through an admin panel. It's not an exemption available under certain elevated permissions. It is a physical fact embedded in the code execution path: data collection runs locally, the ZK circuit runs locally, proof generation runs locally. There is no code path in the entire data processing pipeline that sends raw data to a server. Even if someone obtained every server credential, every database password, every API key — they still couldn't get the user's browsing records, because those records have never existed on the server.
That is what "last line of defense" means.
Encryption can be decrypted. De-identification can be re-identified. Compliance can assign liability after a breach but cannot prevent the breach itself. Architectural constraints cannot be circumvented. It's the difference between a system that is physically incapable of doing something versus a system that is configured to not do something.
To be candid, this design has a real cost. ZK circuits running locally means the computational overhead lands on the user's device rather than a centralized server cluster. Local ZK proof generation has meaningful hardware requirements, and the engineering optimization work involved is substantially greater than centralized server-side processing would be. Every time the team has debated moving ZK computation to the server to improve user experience, we've stopped for the same reason: the moment data leaves the user's device, it no longer belongs entirely to the user.
We've decided that cost is worth paying.
One More Thing, If You've Made It This Far
The past twenty years of internet technology have, in a real sense, been a story of data centers accumulating power and users gradually surrendering control. From local software to SaaS, from owned servers to cloud computing, each technological migration has said the same thing: hand us your things and we'll manage them for you. This narrative holds up in the dimension of convenience. It largely holds up in the dimension of security — professional data centers genuinely are less likely to lose your data than your personal hard drive.
But in one dimension, it has failed completely. Control.
Your photos in the cloud: the cloud provider can see them. Your documents in an online editor: the platform can scan them. Your browser open: dozens of tracking scripts are recording your every move. These behaviors are all technically described as "providing a service," but they all point to the same structural outcome — you no longer own your data. You're merely permitted to access it.
ZK Proof is a technology with the potential to reverse that trajectory.
Not because it's already perfect. Not because it's solved every problem. Not because it's been fully validated at massive production scale. But because it is the only known cryptographic tool capable of simultaneously satisfying two contradictory requirements: data that is useful and data that never leaves you.
DataDID's Data Mining module is one small step in this direction — a concrete product experiment. The proposition we're testing: can a product that helps users earn returns from their data, and a technical architecture that rules out privacy leakage at the structural level, be delivered as a single unified product? If the answer is yes, what changes isn't just the detail of how many points some users accumulate today. What changes is a deep-seated assumption — that for data to generate value, it must be collected, uploaded, and controlled by whoever owns the data center.
Whether ZK Proofs can hold the line, time will tell.
But we've at least put up the load-bearing wall.
Because some things shouldn't depend on trust.