Ethereum in 5 Years: Something You Can’t Imagine Now
Have you ever encountered this situation:
I opened my wallet to transfer money, but the gas fee was higher than the amount I was transferring. After waiting forever, the transaction was still pending. The blockchain was becoming increasingly congested, nodes were running slower and slower, and users were getting more and more frustrated.
This is not an isolated case; it’s a common occurrence for Ethereum users.
But in February of this year, Vitalik published a long technical article that systematically explained Ethereum’s scaling path over the next five years. It wasn’t just empty talk; it had a timeline and phased goals.
Today we’ll discuss what this article actually says and what it means.
I.Ethereum’s Three “Old Problems”
To understand what Vitalik is solving, we first need to figure out exactly where Ethereum is currently stuck.
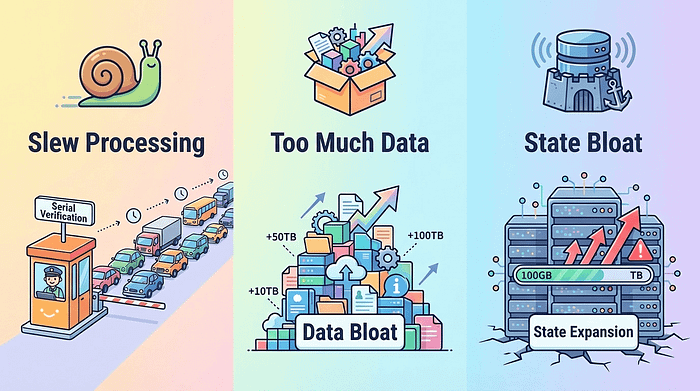
The first problem: I calculate too slowly.
Ethereum currently verifies transactions sequentially, checking them one by one in a queue. If one transaction gets stuck, the rest of the transaction is blocked. It’s like a highway with only one tollbooth; if one car in front can’t find change, everyone else has to wait.
The second problem: too much data.
Every transaction involves data such as the sender, receiver, and signature. As on-chain activity increases, the amount of data that nodes need to process and store is also rapidly expanding. For ordinary people, the barrier to entry for running a node is becoming increasingly high.
The third problem: the more states are accumulated, the heavier they become.
This is the most troublesome of the three. Ethereum’s “state” can be understood as a huge global database that stores all account balances, contract code, and storage data. It’s currently around 100GB, but if it undergoes a large-scale expansion, it could balloon to several terabytes.
The problem wasn’t that the hard drive couldn’t hold the data; rather, database writes were incredibly slow, and synchronizing new nodes could take days. Vitalik himself said there was no “magic bullet” for this problem.
II.How to treat it in the short term? The effects will be felt this year.
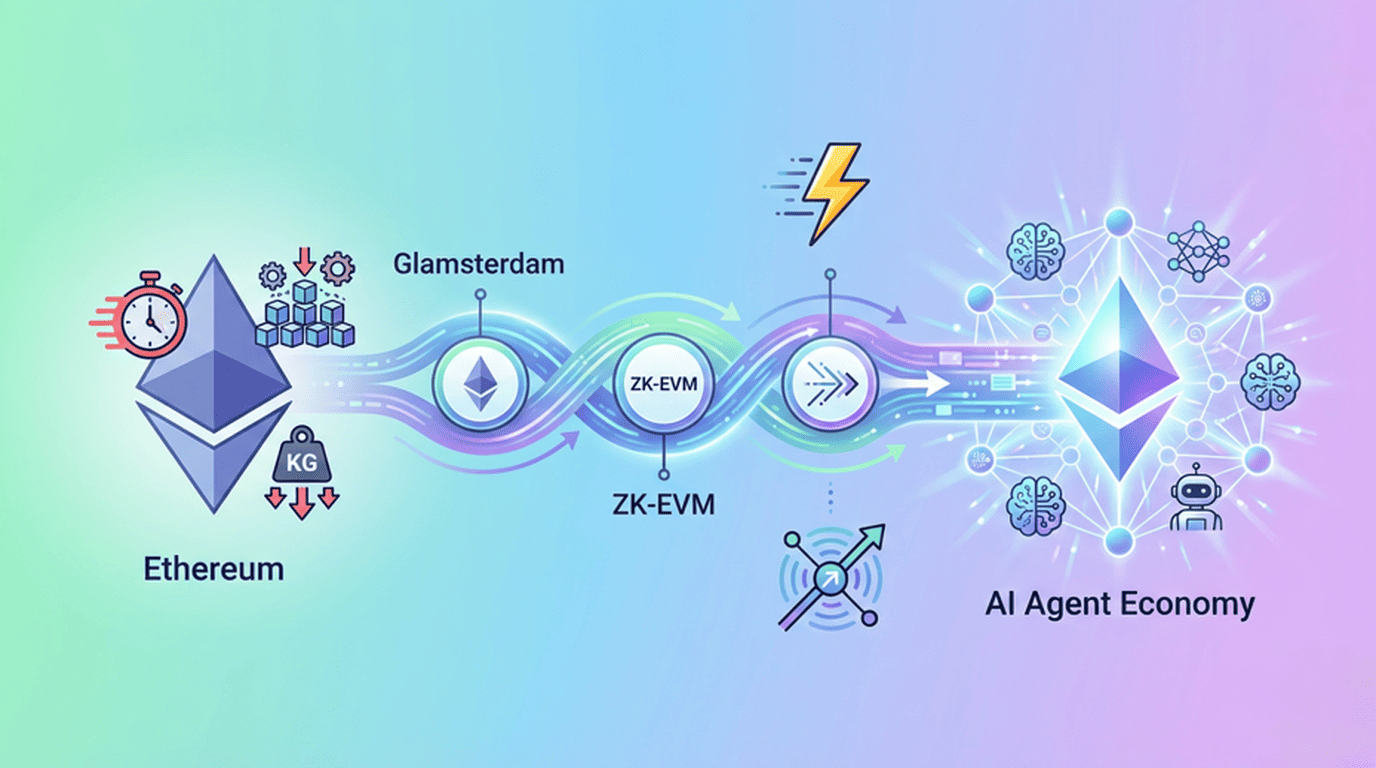
The good news is that the first two problems will be addressed this year, with the core being Ethereum’s upcomingGlamsterdam upgrade.
Parallel Validation: From Single-Lane to Pipeline
After the upgrade, validators can know in advance which accounts and data a transaction in a block will access, so they can load this data in advance and then check multiple transactions in parallel.
Just like a factory going from “one worker making the whole product” to “multiple workers on the assembly line doing different processes at the same time”, efficiency jumps directly.
Gas repricing: Good news for ordinary users
This is the most noteworthy change in the entire upgrade.
Currently, all Ethereum operations are billed using the same gas. Vitalik’s new idea is thatcreating new states (such as deploying contracts or creating new accounts) should be more expensive, but ordinary transfers should be cheaper.
The logic is simple — creating a new state is a permanent occupation, and its cost should be higher. Why should ordinary users, who are simply transferring money, bear this cost?
Using a “reservoir” analogy: From now on, there will be two ledgers, one recording “state creation fees” and the other recording “regular gas fees,” each keeping its own records and no longer mixing them. For ordinary users, transfers will become cheaper. For developers, creating new states will cost more — but if your application is truly valuable, this cost is not a problem.
III.How to treat it long-term? ZK is the answer.
In the short term, we can rely on parallel development and repricing to accelerate growth; in the long term, we need two more significant measures.
ZK-EVM: From “Running it myself” to “Trusting math”
Currently, to verify a block, each node has to re-execute all the transactions in the block. Imagine everyone having to calculate the entire ledger from beginning to end before confirming that the last transaction is correct — this is extremely inefficient.
ZK-EVM’s approach is as follows: someone has already calculated and generated a mathematical proof, and other nodes only need to verify this proof without having to run it again themselves. The verification cost is reduced from “executing all transactions” to “verifying a proof,” theoretically improving efficiency by about 1000 times.
The timeline is also clear: trial use on some nodes in 2026, rollout in 2027, and ultimately mandatory requirement for blocks to include multiple ZK proof types. This isn’t just empty talk; it’s a phased implementation plan.
Blobs + PeerDAS: Verification without downloading the full dataset
Ethereum will use Blobs to store large amounts of data in the future, but if every node has to download all Blobs, the network will be overwhelmed.
PeerDAS’s solution is that nodes only need to download a small portion of the data, and through sampling and ZK proofs, the existence and correctness of the complete data can be confirmed. This is similar to how a statistical survey doesn’t need to ask everyone; sampling can infer the entire population.
When these two technologies are combined, the potential for expanding data resources is approximately 500 times.
IV.The most difficult situation: There is no magic bullet, but there are new ideas.
Having discussed the first two, let’s return to the most difficult issue: state inflation.
To illustrate, Ethereum’s state is like a draft box that can never be cleared. Every time you create a contract or an account, you’re throwing a piece of paper into it. Over the years, the draft box gets fuller and fuller, searches become slower and slower, and it takes newcomers days just to move the draft box home.
Vitalik studied two classic solutions, but both had fundamental flaws. His final solution was to introducea new form of state, giving developers more options:
Temporary storage: Automatically clears monthly, suitable for short-term data such as order books and liquidity pools.
Periodic storage: Reset to zero annually, suitable for medium-term data.
Restricted storage: Accessible only through specific interfaces, facilitating system optimization.
It retains the existing form, but at a higher price.
This approach is actually quite clever — it doesn’t force everyone to change, but rather uses economic leverage to compel developers to optimize themselves. If you want to save money, you have to redesign your application and use a new storage format. If you don’t want to change, fine, but you’ll have to pay more. The overall state growth of the network is thus controlled, while the user experience for ordinary users remains unaffected.
V.Ethereum’s ambitions don’t stop there: All in AI Agent
If you think that the above are all underlying technology optimizations and have nothing to do with the AI wave, then you may really be underestimating Ethereum’s ambitions.
In the current AI boom, Ethereum is doing more than just scaling. At the same time, it is quietly transforming itself into the infrastructure layer of the AI Agent economy.
First, establish a special team
In 2025, the Ethereum Foundation establishedthe dAI Teamwith a single goal: to make Ethereum the preferred settlement and coordination layer for the AI Agent economy, enabling agents to complete payments and collaborations without intermediaries.
Then they launched their own standards and also collaborated with the external ecosystem.
ERC-8004, addresses the question of “who is the other party and is they reliable?” It establishes an on-chain identity and reputation system for each AI Agent, allowing you to directly check an Agent’s historical behavior records and reputation score, instead of blindly trusting a black box.
ERC-8183, a new standard launched this March, was jointly released by the dAI Team and Virtuals Protocol. It addresses the question of “how to trade with confidence.” It introduces the core concept of a Job, breaking down commercial transactions between agents into three roles: the Client that posts the task, the Provider that completes the task, and the Evaluator that acts as the judge. Funds are held in escrow by smart contracts; payments are only released upon task completion, and refunds are issued if the task is unsatisfactory. The entire process requires no platform intervention.
x402, is an open payment protocol launched by Coinbase that solves the “how to pay” problem. It allows agents to complete payments directly, just like calling an API, without manual approval or platform custody. Although it is not a standard led by the Ethereum Foundation, the Ethereum dAI Team has explicitly stated that x402 can be used in combination with ERC-8004 and ERC-8183 to form the foundational protocol layer of the agent economy.
To put it simply:ERC-8004 governs trust, ERC-8183 governs transactions, and x402 governs payments. These three standards each have their own responsibilities, but they all point to the same goal — building a decentralized, autonomous AI agent economic system.

VI.But for the agent to run, one more layer is missing.
Ethereum’s presence in the agent field is already quite comprehensive — it has corresponding protocols for identity, payment, and transactions.
But one question has been overlooked:Where does the agent’s memory come from? Where is the data it generates stored? And who owns this data?
When an agent completes a task, it generates a large amount of data: conversation logs, generated files, knowledge bases invoked, execution results, etc. If this data has nowhere to be stored, or is stored on a centralized server, then the agent is “amnesiac” every time it starts up, and all the previously accumulated context is completely wiped clean. Not to mention the problem of data being controlled by the platform and being able to be deleted or sold at any time.
That’s what MEMO does.
MEMO, based on its own decentralized data chain, integrates protocols such as ERC-8004, x402, and ERC-7829, providing AI Agents with afull lifecycle operating environment from creation, operation, interaction to settlement .
But MEMO’s most core feature is that it createsa memory layer for the Agent.
All files and data generated by the Agent during operation — dialogue logs, task results, and knowledge bases invoked — can be stored in the MEMO network. The Agent can access this data at any time, retaining contextual memory across tasks, instead of starting from scratch each time.
Moreover, this data truly belongs to the users and agents:DataDID establishes data ownership, clarifying data ownership from the source;ERC-7829 turns data into tradable on-chain assets, so your data is not just “stored,” but an asset that can be priced, circulated, and generate value.
If Ethereum builds the transaction market and rule system for agents, then MEMO provides the memory and data foundation that enables agents to truly function . They are not in competition, but rather two indispensable layers of infrastructure.
VII.Conclusion: At the moment of foundation pouring
In every technological revolution, the first thing to emerge is often not the applications, but the infrastructure.
The internet boom occurred after broadband became widespread. The mobile internet boom occurred after 4G was rolled out.
Ethereum is now systematically upgrading its underlying infrastructure — parallel verification, ZK-EVM, a new state architecture, and a whole set of protocol standards specifically designed for AI agents. This isn’t just a small upgrade; it’s a complete rebuild of the foundation.
Once this foundation is solid, the things that can run on it are things we probably can’t even imagine right now.
And we are currently at that moment when “the foundation is being poured”.
These are often the moments that deserve the most attention.