MEMO Original Data Recovery Strategy: Risk-Aware Failure Identification (RAFI)

Conventional decentralized storage systems have high failure rate. In order to tolerate the frequent failures, current systems are using all kinds of redundant techniques with different recovery mechanisms. Such as multi-copy technique or erasure coding.
Data recovery mechanism
Multi-copy technology: Data is stored in fixed length of data chunks with multi-copy. Then place the data chunk replicates on different nodes. If one of the copies is unavailable or lost, it can be recovered by using the rest available copies.
Erasure coding: In the storage system with erasure coding. At first, data is divided in fixed original data chunks. Then the original data chunks will generate a checksum. In the end the original data chunks and the checksum form up a stripe. A stripe is the basic unit to ensure the reliability and availability of the data. Data chunks of the stripes are placed on different nodes. Whenever some of the data chunks are missing or become unavailable in the stripe, the available data chunks can be used to reconstruct the missing data chunks and respond service request. In this way, it can ensure the reliability, availability and service ability of the data.
The common optimization on data recovery
There are 5 methods of optimizing data recovery in the decentralized storage system. They are degrading recovery penalty of the erasure coding, improving recovering rate, optimizing the dispatch of recovering, optimizing data chunk deploy strategy and optimizing failure detection.
1. Degrading recovery penalty of the erasure coding
It takes several times of the erasure coding data to recover it. Which is called the recovery penalty. In order to lower the repair penalty. Researchers start with recovery of the coding, to design a new scheme with a low level of recovery penalty.
2. Raising recovering rate
This method meant to accelerate the data recovery in the system that coding takes effect. Such as adding the network bandwidth, improving the concurrence ability. Thereby, can raise the reliability and availability of data.
3. Optimizing the dispatch of recovering
The recovering dispatch strategy is based on the missing numbers of data chunks in the stripes. When the numbers of the missing data chunks in the stripes are the same. It applies first-come, first-served strategy. Serving the stripes that join recovery array early. When the numbers of the missing data chunks in the stripes are different. It applies precedence strategy. The more missing data chunks in the stripes, the higher priority of recovery they get.
4. Optimizing data chunk deploy strategy
Many new deploy strategies has been mentioned other than random way. For example, some researchers studied the sequential deploy strategy and random deploy strategy. They proposed a stripe deploy strategy to increase the reliability by gathering the small objectives.
5. Optimizing failure detection
Optimizing failure detection is to improve test accuracy and reduce test time by optimizing the failed data. For instance, in some research, historic information and failure rate of the storage nodes are used to estimate the available data chunks in each stripe of the system.
Research emphasis focused on failure detection out of the 5 optimizations.
Conventional identification and recovery process of failed data
1. Failure identification process
In conventional strategy, the data chunk failure identification is based on the failure identification of the node. The system uses the heartbeat mechanism to test if the node fails or not. Nodes send heartbeat messages to the management nodes every 3 seconds. Management nodes monitor the heartbeat message from each node periodically (for instance every 5 minutes). When the management nodes haven’t received the heartbeat information from a certain node. The management nodes identify the node as failure and mark the node a dead node. The data chunk needs to be recovered after being marked as dead. However, the system could waste bandwidth due to triggering the unnecessary recovering process during temporary failure. In order to lower the cost of data recovery after the temporary failure. Data chunks reintegrate into the system right after nodes reconnecting. On account of most node failures are caused by temporary crash or reboot, management nodes will only mark the node as dead when the heartbeat missing exceeded the time of a certain prescribed timeout threshold.
When a node failure is identified, all data chunks are identified as lost. Under the conventional failure identification strategy, the failure identification of all data chunks and nodes share the same timeout threshold.
2. Failure recovery process
When the data chunks’ status is identified as lost. The available data chunks in the corresponding stripes are used to recover the data. Thus, we can ensure the reliability and availability. When the data chunks are failed, the stripe is called a failed stripe. The recovery of the failed stripes follows 3 rules below:
1) The stripes contain more lost data chunks will be recovered prior to the ones contain less. i.e., the stripe contains 2 lost data chunks will be recovered before the one contains 1.
2) Stripes contain the same number of lost data chunks will be dispatched by the principle of first-come, first-serve.
3) To speed up the recovery, system will concurrently recover the idle nodes in the system. It means when there are multiple idle nodes in the system, they will be recovered simultaneously.
Data failure identification
The identification of fail data chunks is on the basis of fail nodes under the conventional strategy mentioned above. The identification time is usually longer than the timeout threshold. Hence, a stripe contains multiple lost data still at the risk of data unavailability or even lost. That’s why a long timeout threshold will tremendously reduce the network flow on the recovery. But it will increase the risk of losing data and lower the reliability.
To ensure the reliability and availability of the data, we need to start data recovery soon as failure happens. However, failure could be temporary, over 90% of the nodes failure duration is within 10 minutes. Therefore, previous recovery of such kind of failure data could cause massive unnecessary recovery flow. Recover a data chunk in the erasure coding system will lead to a network flow transmission several times of it. The recovery flow caused by failures is a very serious problem.
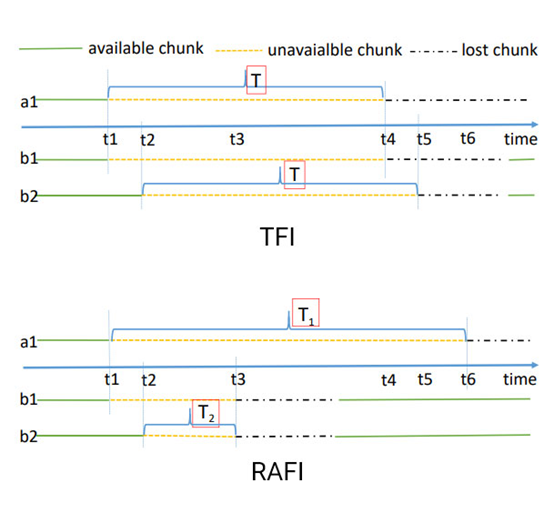
In TFI, a fixed threshold T is used to identify failures. The failure of chunk a1 is not identified until t4, while two failures of chunks b1 and b2 are not identified until t4 and t5, respectively.
In RAFI, the failure of chunk a1 is identified through the threshold T1 at t6, which is later than t4. On the other hand, the failures of chunks b1 and b2 are identified through the threshold T2 at t3,which is ahead of t4 and t5.
Risk-Aware Failure Identification RAFI
MEMO’s original risk-aware failure identification RAFI can help the system to identify failure nodes quickly.
Due to the neglect of the identification time in the conventional scheme for stripe risk category. The data chunks become unavailable during the time of identification. Nevertheless, if another one of the available data chunks in the same stripe fails. Then these failed data chunks can neither be accessed, nor recovered. Thereby it makes the data unavailable. If these failures are permanent, the data is lost.
RAFI won’t classify the stripes according to the missing chunks in the stripes, but to the failed numbers of the data chunks. That contains the numbers of all lost and unavailable data chunks. With such classification for example, a stripe with 2 checksum data chunks. The stripe with 2 failure data chunks is called high risk stripe. The stripe with 1 failure data chunk is called low risk stripe. High risk stripes will be dealt prior to lower the possibility of data unavailability or losing.
The core concept of RAFI is the more failure data chunks there is in a stripe, the less failure identification time will be spent. The system spends different identification time on stripes with different risk levels. For the higher risk stripes with multiple failure data chunks, it’ll spend shorter failure identification time. For the lower risk stripes with a few failure data chunks, it’ll spend longer failure identification time.
Specifically in the erasure coding system, RAFI speed up the identification on the failure data chunks of the high risk stripes which accelerates the recovery of the high risk stripes. At the same time, postpone the identification of the failure data chunks in low risk stripes. This reduces the network flow caused by unnecessary recovery. Sequentially increase the system service ability. During the recovery of high risk stripes, the identification of the failure data chunks is in the dominant position. Thus RAFI can effectively accelerate the recovery of high risk stripes. Thanks to the majority of the stripes to be recovered are with a small amount of failure data. Hence postponing the identification of low risk stripes can effectively lower the network flow caused by recovery.
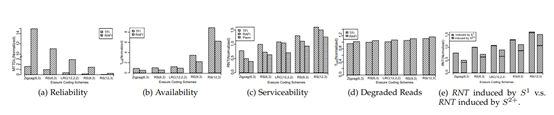

xExperimental results show, in an RS(6,3) coding storage cluster with 1,000 nodes. RAFI can reduce 28% recovery network flow, promote 11 times reliability and decrease 45% unavailable time in the best case scenario compare to conventional strategy. In a triple replica system, RAFI can promote 4 times reliability, at the same time, the extra recovery flow won’t be over 1 % of the total recovery flow. As for the erasure coding system. High repair penalty will cause recovery flow doubles and redoubles, which will drastically influence other services in the system. Therefore, the recovery flow problem is more important in the erasure coding system.
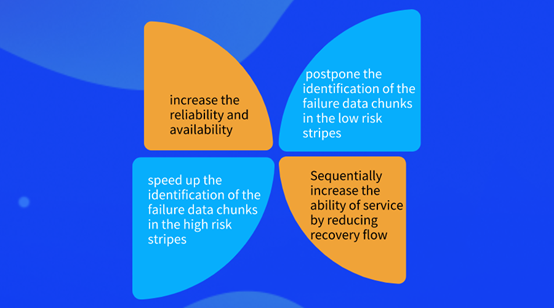
In conclusion, the benefits of RAFI are:
(1) We can speed up the identification of the failure data chunks in the high risk stripes, and increase the reliability and availability;
(2) We can postpone the identification of the failure data chunks in the low risk stripes, and reduce recovery flow. Sequentially increase the ability of service.
Summary: MEMO decentralized cloud storage system originally created RAFI based on the multilevel fault-tolerant mechanism. It greatly boosts up the data recovery and effectively increased the reliability, availability and service ability. As a result, it becomes the core advantage of MEMO Decentralized Cloud Storage.